
Building voice AI that actually feels human has traditionally meant one thing: expensive infrastructure. Large models, specialized hardware, complex pipelines — the conventional wisdom says empathetic AI requires enterprise-level investment.
At Nester Labs, we challenged this assumption. This article documents how we engineered NesterAI — a conversational system that delivers emotionally intelligent voice interactions without breaking the bank.
The Core Hypothesis
Our thesis was simple but contrarian:
“Empathetic voice AI doesn’t require expensive models. By running efficient STT, lightweight emotion detection, and dynamically modulated TTS as parallel pipelines, we can achieve genuine emotional awareness at a fraction of the typical cost.”
To prove this, we needed to optimize three decoupled systems — transcription, emotion detection, and synthesis — each for its specific requirements while maintaining seamless coordination.
Phase 1: Speech-to-Text Selection
The foundation of any voice AI system is accurate, fast transcription. We benchmarked every major STT provider against three criteria: latency, accuracy, and cost efficiency.
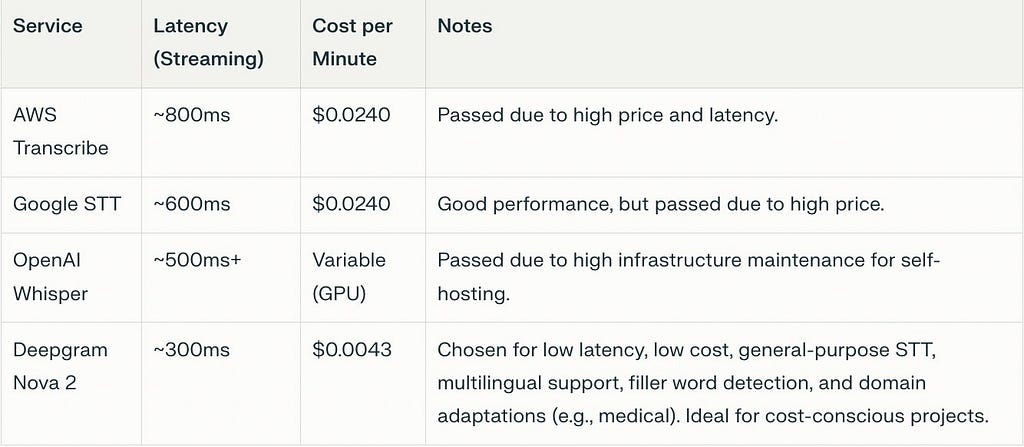
Why We Chose Deepgram Nova 2
After extensive testing, Deepgram Nova 2 emerged as the clear winner for three reasons:
1. Latency Performance
Deepgram delivered sub-300ms latency with 8.4% Word Error Rate (WER). Compare this to:
- OpenAI Whisper: 500-1000ms latency
- Google Cloud Speech: 600ms+ latency
- AWS Transcribe: 600ms+ latency
Why does this matter? Human conversation gaps average around 200ms. Anything slower feels unnatural — like talking to someone on a bad video call. Speed isn’t a feature; it’s the foundation of natural interaction.
2. Cost Efficiency
Deepgram proved to be the cheapest option while performing approximately 2x faster than competitors. For a startup building production systems, this efficiency compounds dramatically at scale.
3. Emotional Capture
Here’s what most teams miss: Deepgram preserves prosodic details that other providers smooth away. Those “umms” and “ahhs”? They’re not noise — they’re emotional signals. A hesitant “um...” before answering carries different emotional weight than confident, immediate speech. Deepgram captures these nuances.
Phase 2: The Emotion Detection Engine
Most voice AI systems rely on text sentiment analysis — essentially running the transcript through a sentiment classifier. This approach has a fundamental flaw: it ignores how something is said.
Consider: “I’m fine.” As text, this is neutral. But spoken with a trembling voice and long pause? That’s clearly not fine.

Parallel Audio Analysis
Instead of analyzing just the transcript, we implemented parallel audio analysis using the wav2vec2-large-robust-12-ft-emotion-msp-dim model (trained on the MSP-PODCAST dataset).
What makes this model special is its output format. Rather than categorical emotions (happy/sad/angry), it outputs dimensional emotions on continuous scales:
- Arousal (0.0-1.0): Energy and activation levels
- Dominance (0.0-1.0): Confidence and control levels
- Valence (0.0-1.0): Positivity vs negativity
This dimensional approach is crucial. Human emotions aren’t discrete categories — we experience blends and gradients. A customer might be “frustrated but hopeful” — something a categorical model can’t capture but dimensional analysis handles naturally.
The Stability Layer
Raw emotion detection is jittery. Minor audio fluctuations can cause rapid emotion flipping, making the AI’s responses feel erratic. We implemented a hysteresis filter with two key mechanisms:
- Consecutive Frame Requirement: The system requires 2 consecutive frames showing the same emotion before triggering a tone shift
- Cooldown Periods: 3-second cooldowns between emotional state changes prevent rapid oscillation
The result: smooth, natural emotional tracking that responds to genuine shifts while ignoring momentary fluctuations.
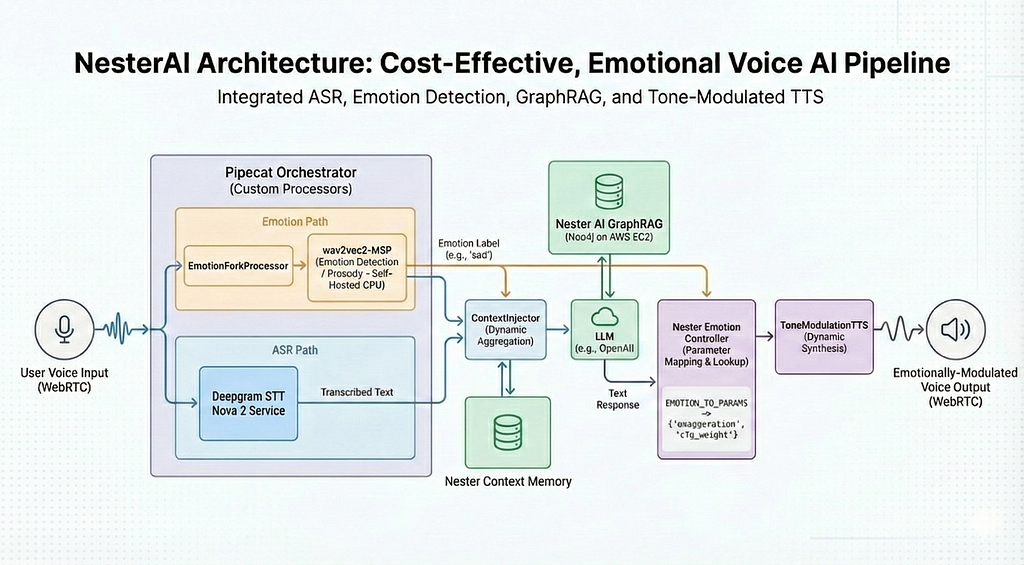
Phase 3: Pipeline Orchestration with Pipecat
Running STT, emotion detection, and LLM inference as separate processes creates coordination challenges. We built on the Pipecat framework but extended it with custom processors:
Custom Processors
- EmotionForkProcessor: Non-blocking audio stream forking that sends audio simultaneously to ASR and spectral analysis pipelines
- ContextInjector: Dynamic GraphRAG data injection that enriches the LLM context pre-inference
- ToneModulationTTS: Per-sentence CFG weight manipulation that adjusts synthesis parameters based on detected emotions
The key innovation is that these processors run in parallel, not sequentially. While transcription happens, emotion analysis runs simultaneously. By the time we have the transcript, we already know the emotional context.
Phase 4: Empathetic Speech Synthesis
The final piece: generating speech that actually sounds empathetic. This is where most voice AI systems fall short — they produce technically accurate but emotionally flat responses.

Why We Chose Chatterbox
After evaluating multiple TTS options, we selected Chatterbox (built on Flow-Matching architecture) for two reasons:
- Latency: Sub-200ms generation time
- Control: Exposed latent parameters for fine-grained tone manipulation
The Build vs. Buy Decision
Initially, we considered self-hosting on A10G GPUs for maximum control. The math didn’t work — infrastructure costs were prohibitive for a startup. We pivoted to a hybrid approach using Resemble AI’s API, enabling pay-as-you-go scaling while maintaining the control we needed.
Emotion-Driven Parameter Control
Chatterbox exposes two key parameters that we manipulate based on detected emotions:
Exaggeration Parameter
Controls pitch variance and expressiveness:
- Low values (0.2-0.4): Subdued, empathetic tone — appropriate for sadness or concern
- High values (0.7-0.9): Energetic, enthusiastic tone — appropriate for excitement or encouragement
CFG Weight
Controls the “tightness” of adherence to the base voice:
- High values (>0.7): Crisp, robotic clarity — useful for factual information
- Low values (0.3-0.5): Introduces human “imperfections” like subtle breathiness and micro-pauses
The Key Distinction
Most TTS systems infer tone from punctuation and text patterns. An exclamation mark triggers excitement; a question mark triggers upward inflection.
NesterAI decouples text from tone entirely. We apply what we call “mathematically induced tremor” — subtle variations based on the detected emotional state, independent of the text content. This means the same sentence can be delivered with genuine concern or matter-of-fact neutrality, depending on the conversational context.
Results and Validation
The architecture validates our core hypothesis: emotional voice AI doesn’t require expensive infrastructure. By optimizing three decoupled systems — each for its specific requirements — we achieved:
- Sub-1.5 second end-to-end latency
- Genuine emotional awareness through parallel audio analysis
- Natural-sounding empathy via dynamic TTS modulation
- Startup-friendly costs through efficient provider selection
What’s Next
This architecture is now powering production voice AI systems at Nester Labs, including healthcare intake coordinators and customer service applications. We’re continuing to refine the emotion detection models and exploring multi-modal approaches that incorporate visual cues.
The broader insight: empathetic AI isn’t about bigger models or more compute. It’s about thoughtful architecture that processes the right signals at the right time.